 Image Reader (OCR)
Image Reader (OCR)

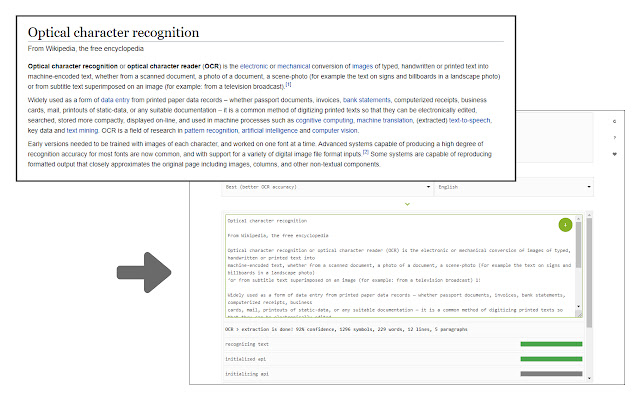


Overview
Image Reader (OCR) is a Chrome extension developed by Sevina.
According to the data from Chrome web store, current version of Image Reader (OCR) is 0.1.6, updated on 2022-10-10.
20,000+ users have installed this extension.
17 users have rated this extension with an average rating of .
Easily get words out of an image with OCR engine!
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info.
To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English.
Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package.
To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
Image Reader (OCR) Alternatives
























Latest Reviews
See More|
2022-05-07
Useless. |
|
2022-04-12
çok iyi |
|
2022-03-14
AMAZING it does miss spell like a super small percentage of letters not whole words only letters in alot of languages thanks alot |
|
2021-12-08
thời gian nhận dạng chữ hơi lâu, mình mất khoảng 50 giây để nhận dạng 1 ảnh |
|
2021-11-05
It would be perfect if you add a screenshot function |